At Allo-Media, like many other businesses, our value chain looks like a pipeline: we collect conversations (mainly through phone) sent to us by our customers, we transcribe them, we tag the transcripts with named entities, we anonymize both the transcript and the audio, then we qualify the content with semantic tags, and finally we index them and provide a UI and API to consult, search, analyze the conversations. All those steps are completed automatically by NLP and AI algorithms.
Such pipelines are well suited for service based architectures. If you need to add a new feature, you introduce a new service into the pipeline.
Our first take at it was based on REST services.
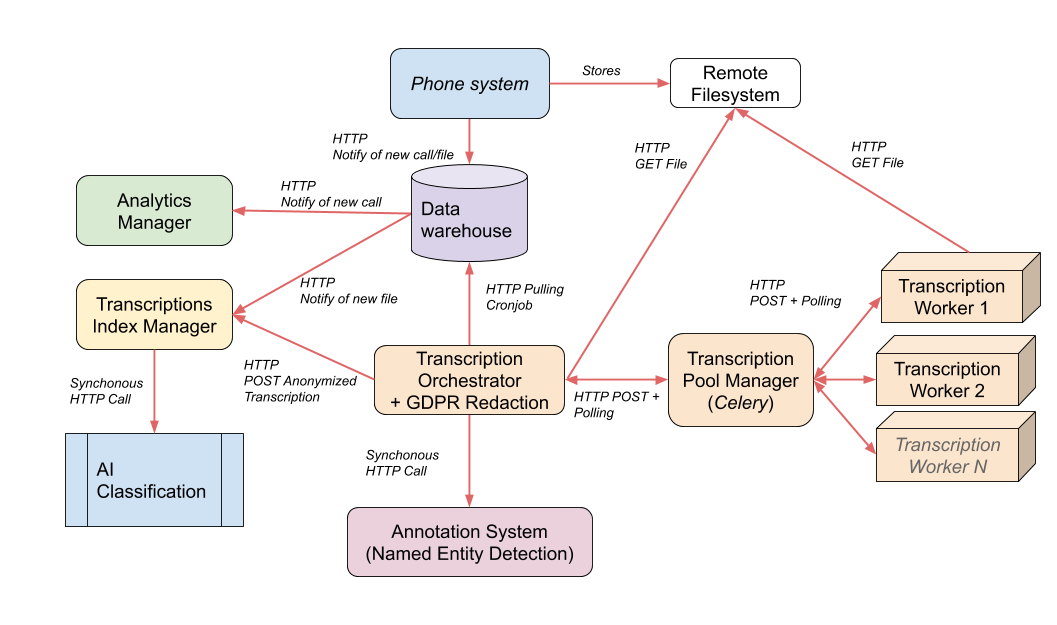
Unfortunately, as you can see on the schema above, that approach had many drawbacks:
- it introduces strong coupling between components, as almost each service has to know about the other related services, their addresses, their purposes, their APIs…;
- load balancing requires ad hoc solutions (like for the Transcription Pool Manager with Celery);
- high availability is tricky because of the synchronous communication: if the requested service is down, the caller has to implement complex “retry later” strategies or give up! And so on for each service.
- upgrading or adding new services is a lot of work as it impacts other services and requires careful coordinated releases. Plus, you have to provide them with IP and DNS addresses.
So one year later, as our activity grew and development accelerated, we quickly realized that we needed:
- maximum service decoupling;
- easy distribution;
- no-brainer load balancing;
- one to one, one to many, many to one, many to many asynchronous communications;
- high availability: hot restart of services, transparent addition or removal of service instances (workers), resilience to (reasonable) downtime of some services;
- support for heavy payloads (megabytes of mp3 audio);
- no data loss, whatever happens.
Enter the event driven architecture
The best way to achieve those goals is to free your mind from the classical pipeline point of view and instead see the value chain as an ecosystem of business services, each focused on providing a specific value and reacting to events (inputs) and producing new events (outputs). This new metaphor has not only technical benefits, but also business and organizational ones. By reasoning in terms of business units of your value chain, its easier to identify the people involved, the business experts who are the references for the job, the exact value added by the service, etc…
Here is the schema of our new architecture:
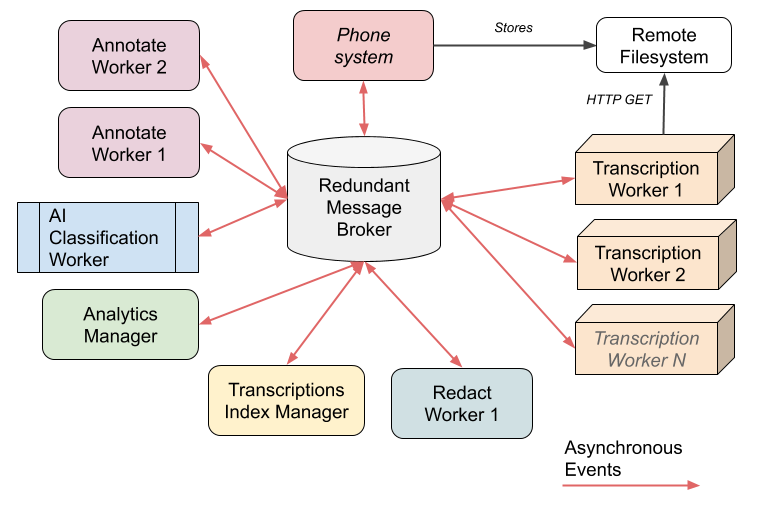
In this new architecture, events are precisely defined messages that streams on a message bus, and each logical service (implementing one such business service as explained above) subscribes to the events that are relevant to it, without needing any knowledge about what produced them and how. They also push their own events on the bus, without caring about what consumes them.
In that way, we completely decouple the services between each other and the message broker running the message bus provides us with load balancing, distribution and high availability for free.
Now, the messages are the API, the only business and technical reference.
After much thinking and experiments, we came with core design principles that are very important for the success of such an event driven architecture and after 4 months of production use, we are very glad we complied with them from the start. But that’s the subject of another blog post coming soon. Stay tuned!